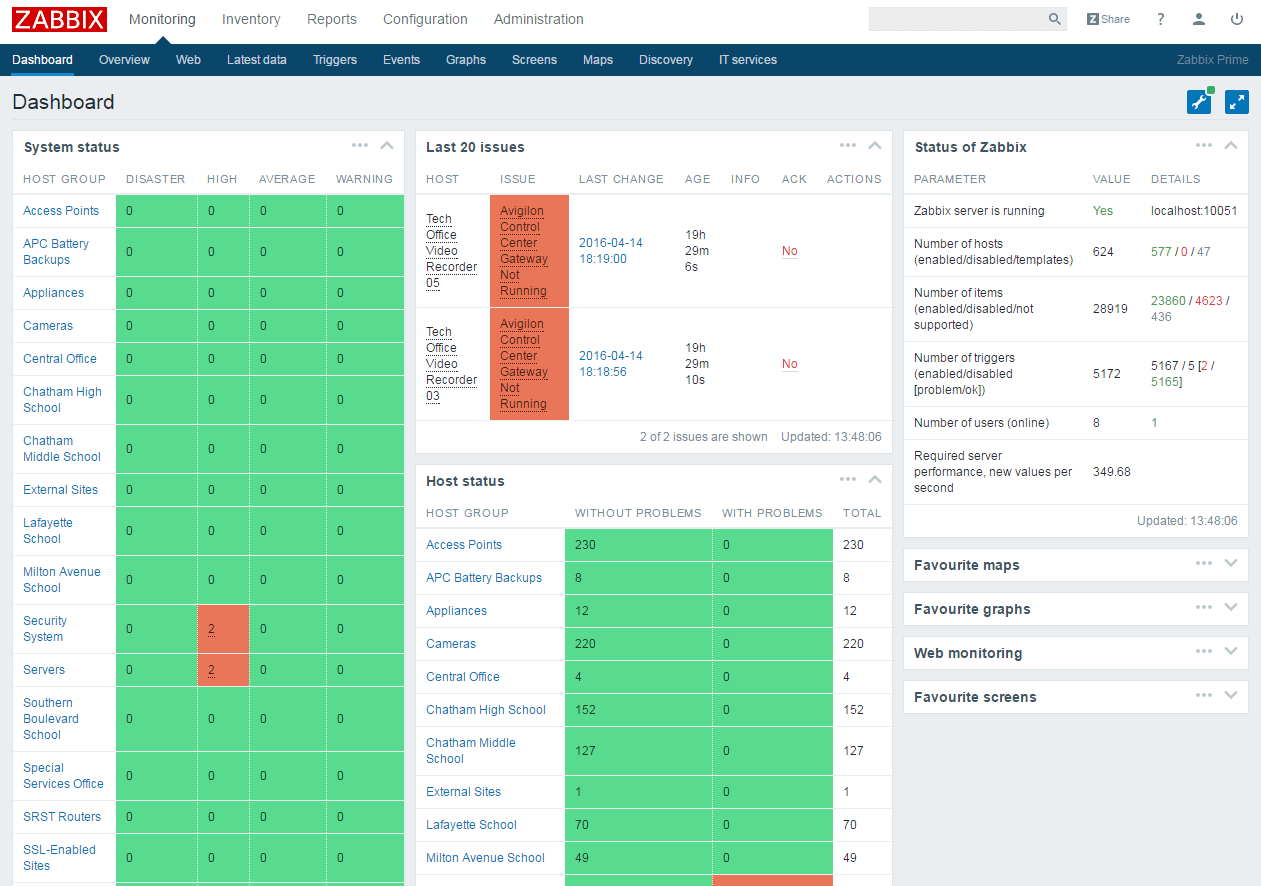
After a week of struggling with Zabbix and getting trigger dependencies done, I figured I was all set. Everything was set to be dependent on something else (usually ping checks to indicate that something is down).
Then we lost connectivity to a school. My email LIT UP with alerts. Almost every single device behind those switches reported that they were down. ARGH!
After doing some more research on it, I found the culprit: how often the data is checked.
I was reading the Zabbix documentation here and the line that got me was: “Before changing the status of the ‘Host is down’ trigger, Zabbix will check for corresponding trigger dependencies. If found, and one of those triggers is in ‘Problem’ state, then the trigger status will not be changed and thus actions will not be executed and notifications will not be sent.”
I interpreted this to mean that if I have two hosts, A and B, with B depending on A that if B went down then Zabbix would IMMEDIATELY turn around and check A. As a real world example:
MAS Main Office IDF Ping Check depends on MAS MDF Ping Check. In theory I expected the following:
- Zabbix checks MAS Main Office IDF Ping via ICMP.
- Result of Step 1 is: 0 (Down).
- Zabbix looks at the trigger and says: this trigger depends on MAS MDF Ping Check.
- Zabbix immediately runs the MAS MDF Ping Check via ICMP.
- Result of Step 4 is: 0 (Down).
- Do not alert about MAS Main Office IDF being down.
- Alert about MAS MDF being down.
- Result of Step 4 is: 1 (Up).
- Alert about MAS Main Office IDF being down.
- Do not alert about MAS MDF (it’s up).
- Result of Step 4 is: 0 (Down).
This is not what happens.
Zabbix DOES check the parent trigger. It checks the last recorded value. So the steps are:
- Zabbix checks MAS Main Office IDF Ping via ICMP.
- Result of Step 1 is: 0 (Down).
- Zabbix looks at the trigger and says: this trigger depends on MAS MDF Ping Check.
- Zabbix immediately checks the last value of the MAS MDF Ping Check via ICMP.
- Result of Step 4 is: 0 (Down).
- Do not alert about MAS Main Office IDF being down.
- Alert about MAS MDF being down.
- Result of Step 4 is: 1 (Up).
- Alert about MAS Main Office IDF being down.
- Do not alert about MAS MDF (it’s up).
- Result of Step 4 is: 0 (Down).
There is a big difference in these scenarios. If the last MAS MDF Ping Check was before the MAS Main Office IDF Ping Check and everything was OK at that particular point in time: well then you’re going to get unnecessary alerts. Grrrr.
The solution, as I’ve found, is to stagger your dependent checks. That is to say: Parent triggers should occur more frequently than child triggers.
For example:
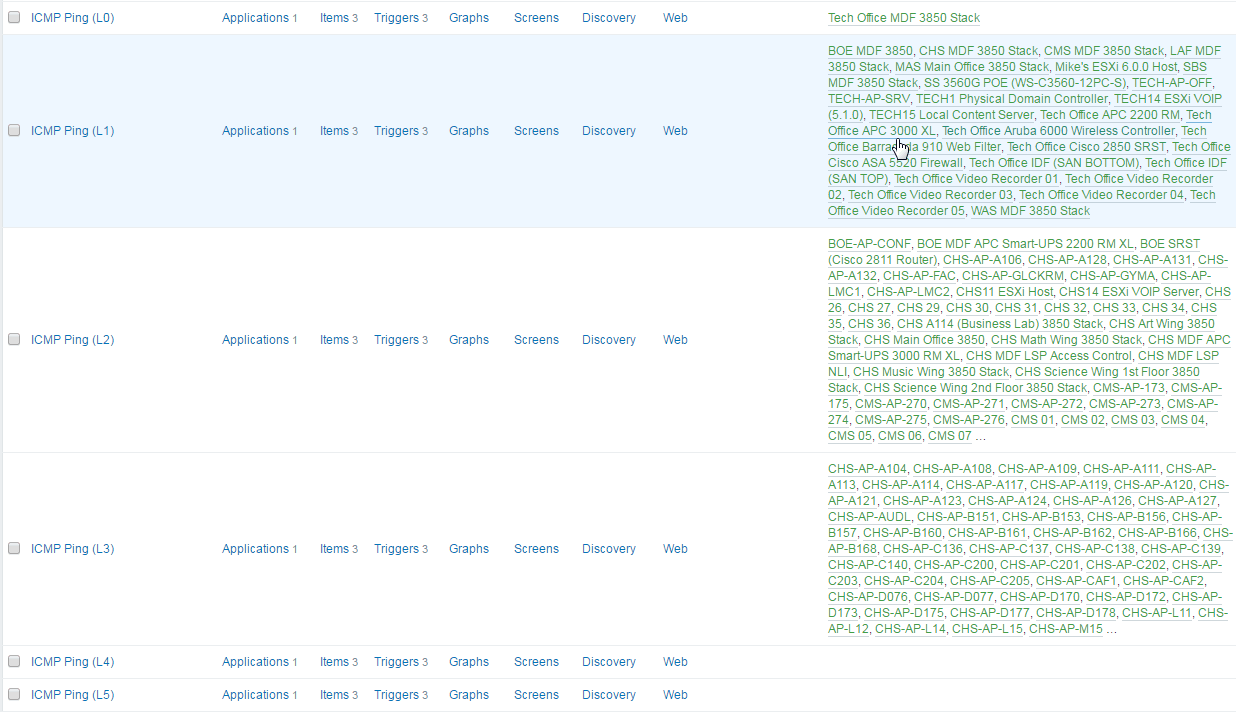
Core -> MDF -> IDF -> Devices. Camera depends on IDF, IDF depends on MDF, MDF depends on Core. There are 4 layers of checks here.
Level 0 Check (Core): Check every 30 seconds.
Level 1 Check (MDF; Anything else immediately behind the core): Check every 60/90 seconds.
Level 2 Check (IDF; Anything else immediately behind the MDF): Check every 120/180 seconds.
Level 3 Check (Devices; Anything else immediately behind the IDF): Check every 240/360 seconds.
I setup the staggered checks by setting up different ping templates per level. I then applied the templates to the hosts.
This morning I arrived at work and low and behold: I had a single alert in my inbox. The CHS Science Wing 1st Floor switch was down. Zabbix indicated a bunch of Cameras and Access Points were down too. But I didn’t get an email about a single one.
Perfection.
On to the next bit: Monitoring RAID arrays and RAID disks. More on that later.
-M, out.